とりあえず、ここあたりがソースとしてはわかりやすいです。
以下、抜粋です。
※<が漢字になってます。注意。
//直線の場合 -------------------------------------------------
int theta,rho;
//直線検出用頻度カウンタ
short[][] counter=new short[THETA_MAX][2*RHO_MAX];
for(y=0;y<YMAX;y++)
for(x=0;x<XMAX;x++)
if(data[y][x]==1){
for(theta=0;theta<THETA_MAX;theta++){
rho=(int)(x*cs[theta]+y*sn[theta]+0.5);
counter[theta][rho+RHO_MAX]++;
}
}
まぁ、中カッコ{}の有無が気に入りませんが、まず、XとYの2重LOOPを回しています。
これは、『画像の全ての点』を対象にしているという意味ですね。
そして、その場所に該当データがあるかどうか、実際には点があるかどうかを判定し、
点があった場合には、1024回のLOOPを回しています。
※THETA_MAXが1024 cs,snはsin,cosを再計算させるのを防止するため(CPU負荷がかかるから)、あらかじめテーブルにいれてあります。
同じ直線上の点であれば、 counter[角度][距離]が同じなので、
++でインクリメントしていきます。 まぁここまでは、だれが書いても似たようなコードになるでしょうかあr、特に問題はありませんですね。(o^^o)
考えるとすれば、THETA_MAXが1024となっていますが、
この適切な値はどうやって決めるかという問題になりますね。
これには、ターゲットとする画像によって違うわけです。
ここでは、800*1200くらいに考えてみると、、、
ヨコ線が左右の端部で1ピクセル上下にズレた直線と仮定すると、
atan(1/800)→0.072度
180/0.072→2500分割くらい必要になります。
よって、上記のサンプルのTHETA_MAXはdefineされていますが、
本来はここは動的にするべきものとなりますね。
さて、上記のrhoは、原点と直線の距離になるわけですが、
どのような値をとりえるかというと、実はマイナス値もとることがわけです。
はやい話、、こういう場合です。
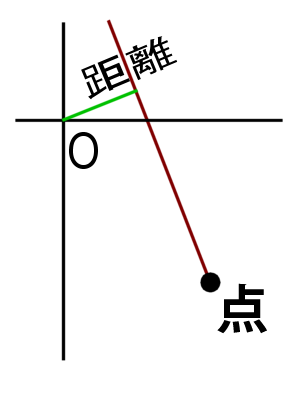
では実際に、どのような値になるかを、
プログラムで確認してみましょう。
つづく